
Decomposing Agency
Desires without capabilities; capabilities without desires


What is an agent? It’s a slippery concept with no commonly accepted formal definition, but informally the concept seems to be useful. One angle on it is Dennett’s Intentional Stance: we think of an entity as being an agent if we can more easily predict it by treating it as having some beliefs and desires which guide its actions. Examples include cats and countries, but the central case is humans.
The world is shaped significantly by the choices agents make. What might agents look like in a world with advanced — and even superintelligent — AI? A natural approach for reasoning about this is to draw analogies from our central example. Picture what a really smart human might be like, and then try to figure out how it would be different if it were an AI. But this approach risks baking in subtle assumptions — things that are true of humans, but need not remain true of future agents.
One such assumption that is often implicitly made is that “AI agents” is a natural class, and that future AI agents will be unitary — that is, the agents will be practically indivisible entities, like single models. (Humans are unitary in this sense, and while countries are not unitary, their most important components — people — are themselves unitary agents.)
This assumption seems unwarranted. While people certainly could build unitary AI agents, and there may be some advantages to doing so, unitary agents are just an important special case among a large space of possibilities for:
Components which contain important aspects of agency (without necessarily themselves being agents);
Ways to construct agents out of separable subcomponents (none, some, or all of which may be reasonably regarded agents in their own right).
We’ll begin an exploration of these spaces. We’ll consider four features we generally expect agents to have1:
Goals
Things they are trying to achieve
e.g. I would like a cup of tea
Implementation capacity
The ability to act in the world
e.g. I have hands and legs
Situational awareness
Understanding of the world (relevant to the goals)
e.g. I know where I am, where the kettle is, and what it takes to make tea
Planning capacity
The ability to choose actions to effectively further their goals, given their available action set and their understanding of the situation
e.g. I’ll go downstairs and put the kettle on
We don’t necessarily expect to be able to point to these things separately — especially in unitary agents they could exist in some intertwined mess. But we kind of think that in some form they have to be present, or the system couldn’t be an effective agent. And although these features are not necessarily separable, they are potentially separable — in the sense that there exist possible agents where they are kept cleanly apart.
We will explore possible decompositions of agents into pieces which contain different permutations of these features, connected by some kind of scaffolding. We will see several examples where people naturally construct agentic systems in ways where these features are provided by separate components. And we will argue that AI could enable even fuller decomposition.
We think it’s pretty likely that by default advanced AI will be used to create all kinds of systems across this space. (But people could make deliberate choices to avoid some parts of the space, so “by default” is doing some work here.)
A particularly salient division is that there is a coherent sense in which some systems could provide useful plans towards a user's goals, without in any meaningful sense having goals of their own (or conversely, have goals without any meaningful ability to create plans to pursue those goals). In thinking about ensuring the safety of advanced AI systems, it may be useful to consider the advantages and challenges of building such systems.
Ultimately, this post is an exploration of natural concepts. It’s not making strong claims about how easy or useful it would be to construct particular kinds of systems — it raises questions along these lines, but for now we’re just interested in getting better tools for thinking about the broad shape of design space. If people can think more clearly about the possibilities, our hope is that they’ll be able to make more informed choices about what to aim for.

Familiar examples of decomposed agency
Decomposed agency isn’t a new thing. Beyond the complex cases of countries and other large organizations, there are plenty of occasions where an agent uses some of the features-of-an-agent from one system, and others from another system. Let’s look at these with this lens.
To start, here’s a picture of a unitary agent:

They use their planning capacity to make plans, based on both their goals and their understanding of the situation they’re in, and then they enact those plans.
But here’s a way that these functions can be split across two different systems:

In this picture, the actor doesn’t come up with plans themselves — they outsource that part (while passing along a description of the decision situation to the planning advisor).
People today sometimes use coaches, therapists, or other professionals as planning advisors. Although these advisors are humans who in some sense have their own goals, professional excellence often means setting those aside and working for what the client wants. ChatGPT can also be used this way. It doesn’t have an independent assessment of the user’s situation, but it can suggest courses of action.
Here’s another way the functions can be split across two systems:

People often use management consultants in something like this role, or ask friends or colleagues who already have situational awareness for advice. Going to a doctor for tests and a diagnosis that they use to prescribe home treatment is a case of using them as a planning oracle. The right shape of AI system could help similarly — e.g. suppose that we had a medical diagnostic AI which was also trained on which recommendations-to-patients produced good outcomes.
The passive actor in this scenario need not be a full agent. One example is if the actor is the legal entity of a publicly traded firm, and the planning oracle is its board of directors. Even though the firm is non-sentient, it comes with a goal (maximize shareholder value), and the board has a fiduciary duty to that goal. The board makes decisions on that basis, and the firm takes formal actions as a result, like appointing the CEO. (The board may get some of its situational awareness from employees of the firm, or further outsource information gathering, e.g. to a headhunting firm.)
Here’s another possible split:
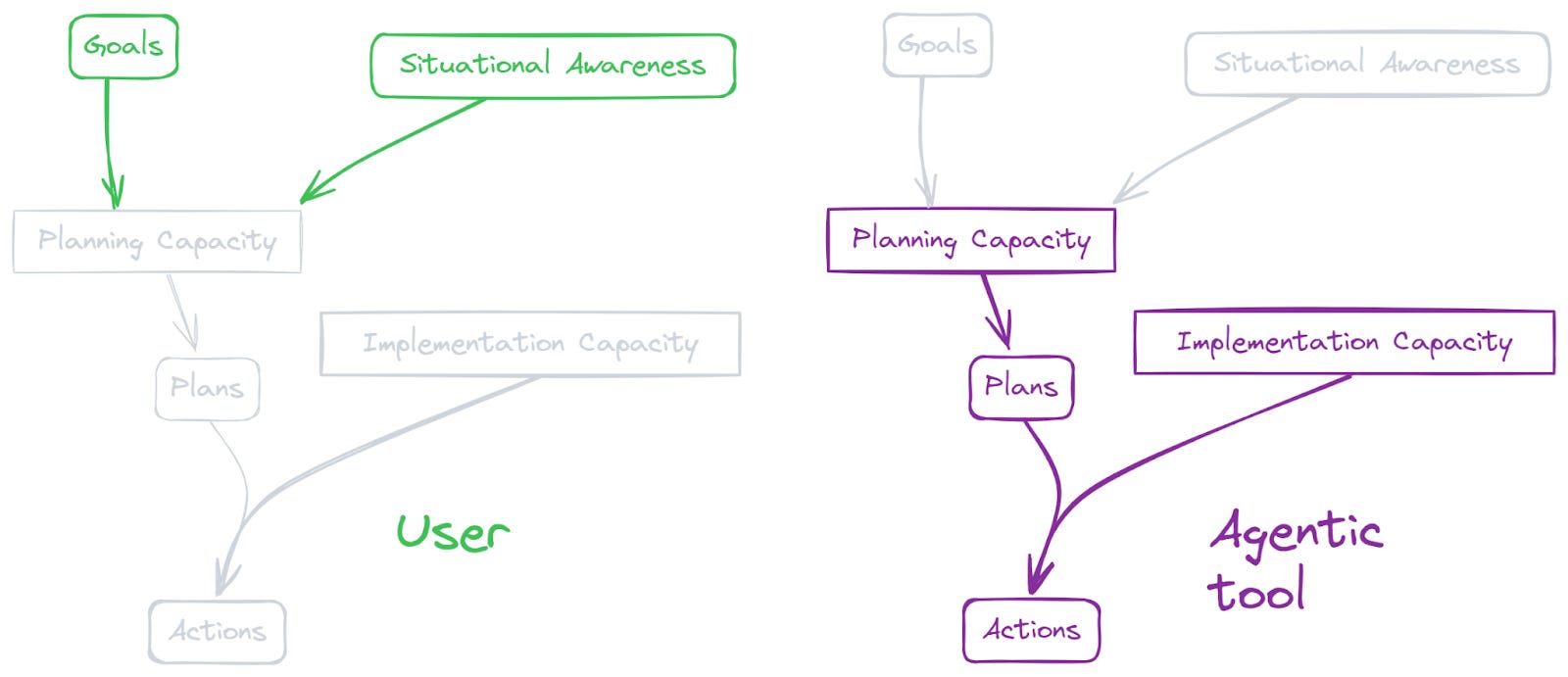
Whereas a pure tool (like a spade, or an email client configured just to send mail) might provide just implementation capacity, an agentic tool does some of the thinking for itself. Alexa or Siri today are starting to go in this direction, and will probably go further (imagine asking one of them to book you a good restaurant in your city catering to particular dietary requirements). Lots of employment also looks somewhat like this: an employer asks someone to do some work (e.g. build a website to a design brief). The employee doesn’t understand all of the considerations behind why this was the right work to do, but they’re expected to work out for themselves how to deal with challenges that come up.
(In these examples the agentic tool is bringing some situational awareness, with regard to local information necessary for executing the task well, but the broader situational awareness which determined the choice of task came from the user.)
And here’s a fourth split:

One archetypal case like this is a doctor, working to do their best by the wishes of a patient in a coma. Another would be the executors of wills. In these cases the scaffolding required is mostly around ensuring that the incentives for the autonomous agent align with the goals of the patient.
(A good amount of discussion of aligned superintelligent AI also seems to presume something like this setup.)
AI and the components of agency
Decomposable agents today arise in various situations, in response to various needs. We’re interested in how AI might impact this picture. A full answer to that question is beyond the scope of this post. But in this section we’ll provide some starting points, by discussing how AI systems today or in the future might provide (or use) the various components of agency.
Implementation capacity
We’re well used to examples where implementation capacity is relatively separable and can be obtained (or lost) by an agent. These include tools and money2 as clear-cut examples, and influence and employees3 as examples which are a little less easily separable.
Some types of implementation capacity are particularly easy to integrate into AI systems. AI systems today can send emails, run code, or order things online. In the future, AI systems could become better at managing a wider range of interfaces — e.g. managing human employees via calls. And the world might also change to make services easier for AI systems to engage with. Furthermore, future AI systems may provide many novel services in self-contained ways. This would broaden the space of highly-separable pieces of implementation capacity.
Situational awareness
LLMs today are good at knowing lots of facts about the world — a kind of broad situational awareness. And AI systems can be good at processing data (e.g. from sensors) to pick out the important parts. Moreover AI is getting better at certain kinds of learned interpretation (e.g. medical diagnosis). However, AI is still typically weak at knowing how to handle distribution shifts. And we’re not yet seeing AI systems doing useful theory-building or establishing novel ontologies, which is one important component of situational awareness.
In practice a lot of situational awareness4 consists of understanding which information is pertinent. It’s unclear that this is a task at which current AI excels; although this may in part be a lack of training. LLMs can probably provide some analysis, though it may not be high quality.
Goals
Goals are things-the-agent-acts-to-achieve. Agents don’t need to be crisp utility maximisers — the key part is that they intend for the world to be different than it is.
In scaffolded LLM agents today, a particular instance of the model is called, with a written goal to achieve. This pattern could continue — decomposed agents could work with written goals5.
Alternatively, goals could be specified in some non-written form. For example, an AI classifier could be trained to approve of certain kinds of outcome, and then the goal could specify trying to get outcomes that would be approved of by this classifier. Goals could also be represented implicitly in an RL agent.
(How goals work in decomposed agents probably has a lot of interactions with what those agents end up doing — and how safe they are.)
Planning capacity
We could consider a source of planning capacity as a function which takes as inputs a description of a choice situation and a goal, and outputs a description of an action which will be (somewhat) effective in pursuit of that goal.
AI systems today can provide some planning capacity, although they are not yet strong at general-purpose planning. Google Maps can provide planning capacity for tasks that involve getting from one place to another. Chatbots can suggest plans for arbitrary goals, but not all of those plans will be very good.
Planning capacity and ulterior motives
When we use people to provide planning capacity, we are sometimes concerned about ulterior motives — ways in which the person’s other goals might distort the plans produced. Similarly we have a notion of “conflict of interest” — roughly, that one might have difficulty performing the role properly on account of other goals.
How concerned should we be about this in the case of decomposed agents? In the abstract, it seems entirely possible to have planning capacity free from ulterior motives. People are generally able to consider hypotheticals divorced from their goals, like "how would I break into this house" — indeed, sometimes we use planning capacity to prepare against adversaries, in which case the pursuit of our own goals requires that we be able to set aside our own biases and values to imagine how someone would behave given entirely different goals and implementation capacity.
But as a matter of practical development, it is conceivable that it will be difficult to build systems capable of providing strong general-purpose planning capacity without accidentally incorporating some goal-directed aspect, which may then have ulterior motives. Moreover, people may be worried that the system developers have inserted ulterior motives into the planning unit.
Even without particular ulterior motives, a source of planning capacity may impose its own biases on the plans it produces. Some of these could seem value-laden — e.g. some friends you might ask for advice would simply never consider suggesting breaking the law. However, such ~deontological or other constraints on the shape of plans are unlikely to blur into anything like active power-seeking behaviour — and thus seem much less concerning than the general form of ulterior motives.
Scaffolding
Scaffolding is the glue which holds the pieces of the decomposed agent together. It specifies what data structures are used to pass information between subsystems, and how they are connected. This use of “scaffolding” is a more general sense of the same term that is used for structures around LLMs to turn them into agents (and perhaps let them interface with other systems like software tools).
Scaffolding today includes the various UIs and APIs that make it easy for people or other services to access the kind of decomposed functionality described in the sections above. Underlying technologies for scaffolding may include standardized data formats, to make it easy to pass information around. LLMs allow AI systems to interact with free text, but unstructured text is often not the most efficient way for people to pass information around in hierarchies, and so we suspect it may also not be optimal for decomposed agents. In general it’s quite plausible that the ability to build effective decomposed agents in the future could be scaffolding-bottlenecked.
Some questions
All of the above tells us something about the possible shapes systems could have. But it doesn’t tell us so much about what they will actually look like.
We are left with many questions.

Possibility space
We’ve tried to show that there is a rich space of (theoretically) possible systems. We could go much deeper on understanding this:
We carved up agency into four key features, but are other carvings more natural?
As we’ve seen in several examples, sometimes provision of one of the features is split across multiple systems. Is there a natural way to account for that?
Are some features naturally linked to others, so that it’s particularly difficult (in some sense) to separate them?
Among the properties we may think of as typical of agents, which are robustly typical of agents, and which may be just typical of unitary agents?
What’s the role of perception?
Our analysis hasn’t distinguished between:
Static sources of perception (like an encyclopedia);
Active sources of perception (like a movable camera that can be directed by the agent’s actions);
Planning-relevant understanding (like knowing that this is the ball that is ultimately important and so you might want to keep your eye on)
Does this cause us to miss relevant subtleties?
Are there natural obstructions to populating parts of the possibility space with real systems?
Even if they’re all eventually reachable, will some parts have big technical challenges to achieving?
Is it more natural to think of scaffolding first (i.e. have the scaffolding, and then work out systems to interface with it in the different slots) or second (i.e. start with the component systems and build the scaffolding to fit them together), or is this a confused question?
How much path dependence might we expect in terms of what is developed?
Efficiency
What is efficient could have a big impact on what gets deployed. Can we speak to this?
What are the relevant types of efficiency or inefficiency?
Training efficiency
How difficult is it to create an effective agent of a given type?
Runtime efficiency
How good at reaching good decisions is a particular agent, as a function of the resources it uses to make those decisions?
Efficiency of internal data management
There can be a meaningful cost to transferring the necessary context between agent components (e.g. feeding goals and especially situational awareness into the piece which provides planning capacity)
There are questions about how much good scaffolding can render these costs small or irrelevant (e.g. we’re already seeing AI assistants with persistent memory)
Reliability
How consistent are the systems in generating certain types of behaviour?
How confident can we be in that?
Legibility / interfaces
For some applications, something like “efficiency at being legible” — the ability to be legible could be significantly helpful in cases where trust is needed (and decomposition may aid legibility)
Upgradeability
For what contexts/applications is it useful to be able to upgrade parts of the system piecemeal, rather than replacing the whole system? How much does this matter?
Others?
How might different types of decomposition create efficiencies or inefficiencies?
What about outsourcing?
AI systems today sometimes benefit from outsourcing to other AI systems. Can we understand what determines when that is efficient or inefficient?
e.g. when is it better to have several specialist systems vs one larger generalist system?
Can we understand what drives the cases where it is efficient for humans to decompose agency, as in the examples discussed above?
Would greater efficiency at decomposing agency lead to a shift of power away from actors who are naturally unitary (like individual humans) and towards ones which are naturally decomposed (like institutions)?
Safety
People have various concerns about AI agents. These obviously intersect with questions of how agency is instantiated by AI systems:
Can people build systems which very reliably perform each of the parts of agency by itself?
Under what circumstances might we see agency emerging accidentally?
Can decomposing systems make it easier to scrutinise components and validate them to meaningful standards?
Could decomposed agents make it easier to have strong cognitive transparency?
Could decomposition make it easier to verify certain safety properties?
Or to build systems which have these properties by design?
How do notions like power-seeking and instrumental convergence extend to non-unitary agents?
What would the societal risks be of deploying powerful systems of this form?
How might society appropriately react to keep high levels of safety?
How feasible is it to restrict the creation of certain kinds of system?
How much does creating weak systems with no guarantees on their behaviour matter, if the strongest systems are built in a way that permits good auditing of their safety?
What options might we be choosing between, if we’re considering things other than “people build all possible systems”?
So what?
Of all the ways people anthropomorphize AI, perhaps the most pervasive is the assumption that AI agents, like humans, will be unitary.
The future, it seems to us, could be much more foreign than that. And its shape is, as far as we can tell, not inevitable. Of course much of where we go will depend on local incentive gradients. But the path could also be changed by deliberate choice. Individuals could build towards visions of the future they believe in. Collectively, we might agree to avoid certain parts of design space — especially if good alternatives are readily available.
Even if we keep the basic technical pathway fixed, we might still navigate it well or poorly. And we're more likely to do it well if we've thought it through carefully, and prepared for the actual scenario that transpires. Some fraction of work should, we believe, continue on scenarios where the predominant systems are unitary. But it would be good to be explicit about that assumption. And probably there should be more work on preparing for scenarios where the predominant systems are not unitary.
But first of all, we think more mapping is warranted. People sometimes say that AGI will be like a second species; sometimes like electricity. The truth, we suspect, lies somewhere in between. Unless we have concepts which let us think clearly about that region between the two, we may have a difficult time preparing.
Acknowledgements
A major source of inspiration for this thinking was Eric Drexler’s work. Eric writes at AI Prospects.
Big thanks to Anna Salamon, Eric Drexler, and Max Dalton for conversations and comments which helped us to improve the piece.
Of course this isn’t the only way that agency might be divided up, and even with this rough division we probably haven’t got the concepts exactly right. But it’s a way to try to understand a set of possible decompositions, and so begin to appreciate the scope of the possible space of agent-components.
Money is a particularly flexible form of implementation capacity. However, deploying money generally means making trades with other systems in exchange for something (perhaps other forms of implementation capacity) from them. Therefore, in cases where money is a major form of implementation capacity for an agent, there will be a question of where to draw the boundaries of the system we consider the agent. Is it best if the boundary swallows up the systems that are employed with money, and so regards the larger gestalt as a (significantly decomposed) agent?
(This isn’t the only place where there can be puzzles about where best to draw the boundaries of agents.)
We might object “wait, aren’t those agents themselves?”. But pragmatically, it often seems to make sense to regard as sophisticated-implementation-capacity of the larger agent something that implicitly includes some local planning capacity and situational awareness, and may be provided by an agent itself.
Some situational awareness is about where the (parts of the) agent itself can be found. This information should be easily provided in separable form. Because of safety considerations, people are sometimes interested in whether systems will spontaneously develop this type of situational awareness, even if it’s not explicitly given to them (or even if it’s explicitly withheld).
One might worry that written goals would necessarily have the undesirable feature that, by being written down, they would be forever ossified. But it seems like that should be avoidable, just by having content in the goals which provides for their own replacement. Just as, in giving instructions to a human subordinate, one can tell them when to come back and ask more questions, so too a written goal specification could include instructions on circumstances in which to consult something beyond the document (perhaps the agentic system which produced the document).
 | A guest post by
|